

AIが“画像を描く”時代は終わり、いまや“人間と共に編集する”時代へ――。
Googleが発表した Gemini 2.5 Flash Image(コードネーム:Nano Banana) は、単なる生成AIではなく、写真・イラスト・構図を「理解し、整え、再構築」する次世代の画像編集AIです。
被写体の一貫性を保ち、光や背景を自然に変えるその精度は、Photoshopでも再現困難なレベル。
この記事では、Nano Bananaの仕組みから使い方、商用利用の注意点、そしてプロが実践する編集テクニックまでを、最新情報と実例をもとに徹底解説します。
AI編集革命の最前線――その“バナナの皮一枚分先”を覗いてみましょう。
Nano Bananaとは?──Googleが放つ“画像編集AIの革命”

Nano Bananaは、Google Gemini 2.5 Flash Imageの内部コードネームとして注目を集める次世代AIです。従来の「画像を作るAI」ではなく、「既存画像を“理解して編集”できるAI」。キャラの一貫性を維持したまま背景・構図を変えるなど、人間の“ディレクション意図”をくみ取るのが特徴です。本章では、その正体と登場の背景、既存モデルとの根本的な違いを掘り下げます。
Nano Bananaの正体:Gemini 2.5 Flash Imageとの関係
Gemini 2.5 Flash Image(通称“Nano Banana”)は、Googleが発表した最先端の画像生成・編集モデルです。2025年8月26日に正式公開され、テキスト指示+画像入力という形式で、「画像の既存要素を理解して編集・再構成する」機能を大幅に強化しています。
「Nano Banana」という呼称は、正式名称ではなく、モデルのコードネームまたは通称としてネット上で用いられ始めたものです。Google自身も発表の中で “aka nano-banana” と記載しています。
このモデルの核となるのは、単に“新しい画像を生成する”機能ではなく、写真や既存画像を「文脈を理解して改変」できる点です。例えば、人物の立ち位置・背景・ライティング・構図などを解析し、「この人物を夜景にして」「背景だけ変えて」「服の色を変えて」などの自然言語指示に応じて編集できます。
さらに、複数の画像を入力して一枚のシーンに合成する「マルチイメージフュージョン」もサポートされており、広告、カタログ、商品撮影のレタッチなど多用途に対応できる設計です。
こうした機能により、クリエイターが抱えていた「同一キャラクター/商品を異なるシーンに登場させても違和感が出る」「編集を重ねると破綻する」といった課題を大幅に軽減する方向へ進化しています。実際、モデルカードには「Character & style consistency」「Real-world knowledge」といった項目が明記されています。
以上の点から、Nano Banana=Gemini 2.5 Flash Imageという関係は確実と言え、「編集AIとしての新ステージ」を象徴しています。
コードネームの意味と誕生背景
「Nano Banana」という名称自体はユーモラスですが、背後には技術とプロダクト戦略が隠れています。まず「Nano(ナノ)」という語は、小さい/軽量/高速というニュアンスを持ち、リアルタイム編集やモバイル環境適用を視野に入れた設計がされていることを示唆しています。実際、Googleの発表では “low latency, cost-effectiveness, ease of use” といったキーワードが並び、軽快な応答性が明示されています。
一方「Banana(バナナ)」という語は、Google社内のプロジェクトやモデルのコードネームとして過去にも散見されており、開発初期段階の仮称として用いられていたようです。例えば「Nano Banana」というコードネームは、公開前のベンチマークコミュニティ(例えば LMArena)で記録されていました。
このプロジェクトが生まれた背景には、生成AI/編集AI分野における“連続性”“一貫性”の壁があります。従来、AIで画像を生成すると高品質な1枚は得られるものの、「同じキャラクターを複数のシーンに」「商品を色/角度を変えて多数生成」「ある構図を保持しつつ背景だけ変える」といった編集・流用が難しいという声が多く上がっていました。実例として、編集後に顔のバランスが崩れたり、手の指が多かったりといった“破綻”が頻発していました。
Googleはこの課題に対して、同社のマルチモーダルAIフレームワークであるGeminiシリーズを拡張し、「画像理解 → 編集指示 →再構成」というフローをリアルタイムに実現するためのモジュールとして、Gemini 2.5 Flash Imageを開発しました。コードネーム “Nano Banana” は、まさに「軽量かつ高速に編集できるバナナ(=スナックのように気軽に使える)」という開発チームの発想を反映していると推定されます。
このように、名前自体に“使いやすさ”“高速性”“編集志向”という思想が込められており、プロダクトが“生成”より“編集”に主眼を移していることを象徴しています。
既存AI画像生成との違い(生成ではなく“編集”に革命)
AIによる画像生成技術はここ数年、飛躍的に進化してきました。例えばMidjourney、Stable Diffusionといったモデルは、テキストプロンプトから驚くほど美しい独立した画像をゼロから生成する能力を持っています。一方で、その成果を「リアル世界の写真に近づけて編集」したり、「既存素材を活用してシーンを変更」したりといった用途には限界がありました。
主な課題としては:
- 同一キャラクター/被写体を複数のシーンや角度で登場させると、見た目や表情の一貫性が崩れる。
- 複雑な背景変更や構図維持を伴う編集では、ノイズや破綻が入りやすく、修正に多くの手間がかかる。
- 編集のためのテンプレート化・再利用性・商品カタログのような量産用途では、理想的なワークフローが組みにくかった。
これに対して、Gemini 2.5 Flash Image(Nano Banana)は「編集」をキーワードに据え直しています。特に以下の点が既存モデルと異なります:
- キャラクター・スタイルの一貫性:一度登場した被写体を、別の背景や角度・衣装で登場させても、AIが「同じ人/同じ商品」であることを認識・維持します。
- ナチュラル言語による編集指示:プロンプトに「この背景を夜景にして」「この椅子を青くして」「この人物を笑顔にして」と入力するだけで、AIが画像内の構造・構図・光源まで理解して再構成します。
- マルチイメージ融合・再構成:複数の参考画像をアップロードし、それらを統合して1枚の新しい画像に編集/生成することが可能。例えば、商品を複数アングルで撮影して、それを1シーンにまとめるような編集が効率的に行えます。
このように、従来の「生成」主体モデルに対して、Nano Bananaは「既存画像編集/再利用」「構図・キャラの一貫性」「高速対話型ワークフロー」という観点から“革命的な一歩”を踏み出したと言えます。ただし、完璧というわけではなく、公式ドキュメントには「小さな顔・細かな文字表現・複雑な手の構造には依然改善余地あり」と明記されています。
つまり、「生成AI」から「編集AI」へ――それがこのモデルが提示した次の段階であり、クリエイター・企業利用者双方にとって大きな価値転換をもたらしています。
🎁 今だけ豪華4大特典プレゼント!

- 🎁 Amazon Kindle出版:AI漫画0→1突破ウェビナー
- 🎁 【画像生成とプロンプト】ゼロから始めるAI漫画
- 🎁 【Anifusionの使い方】ゼロから始めるAI漫画
- 🎁 【Anifusionの使い方】実演編
公式LINEに登録するだけで上記の豪華特典を4個プレゼント!
後にプレゼント停止の可能性もあるので今のうちにゲットしてください。
何がスゴい?Nano Bananaの核心機能と特徴

Nano Bananaの最大の強みは“自然文での指示理解”と“構図保持編集”。「この写真の人物を夜の街で撮ったようにして」などの曖昧な依頼にも正確に応じます。さらに、光源補正や背景統合、ノイズ除去をAIが自動的に最適化。生成ではなく、実写レベルで“補う”技術こそ革新の中核です。ここでは主要機能と、その裏にあるAIアーキテクチャの違いを整理します。
キャラクター・構図の一貫性を保つ画像編集
「同じ被写体を別シーンでも同じ顔/雰囲気で登場させたい」――この世にクリエイターにとって永遠の悩みのひとつでした。しかし Gemini 2.5 Flash Image(通称「Nano Banana」)は、この「キャラクター・一貫性(character-consistency)」という壁をかなり高いレベルで突破しています。
従来の画像生成・編集AIでは、例えば「この人物を別の背景に移したい」「同一商品の別角度を作りたい」「漫画キャラを別シーンでも使いたい」といった用途で、何度か編集を重ねるうちに被写体の表情・輪郭・スタイルがズレてしまったり、“別人感”が出てしまったりすることが、常に課題でした。Nano Bananaでは、Googleが発表している通り「maintain the appearance of a character or object across multiple images and scenes」などの機能に注力しています。
具体的には、ある写真をアップロードし「この人物を夕暮れのビーチに立たせて」「この商品の色を赤にして、背景は夜景にして」などと指示した際、人物の顔立ち・髪型・着衣の雰囲気を大きく変えずに、新しい構図・光源・背景だけを自然に変更してくれるというもの。これは「生成」ではなく「編集+再構成」のアプローチだからこそ実現可能となっています。たとえば、製品カタログで “同一商品を複数シーンで見せる” といった用途で極めて有効です。
さらに、ブランド素材やキャラクター素材を量産したいクリエイターにとってこの一貫性は、手動で整える手間を大幅に削減します。1回目の生成のあと、別シーン・別構図でも同キャラを被写体として “違和感なく”登場させられるため、統一感あるヴィジュアル資産を短期間で大量に作れる可能性があります。レビュー記事では「character-consistency, multi-image fusion, prompt-based editing」などが主要な評価ポイントに挙げられています。
ただし、公式ドキュメントでは「完璧ではない(small faces, fine details)」「キャラクターフィーチャーの維持にまだ改善余地あり」と明記されています。
つまり、非常に高いレベルの一貫性を実現してはいるものの、極めて細かな顔のパーツや背景複雑構図では、プロが手作業で微調整する余地が残っているということです。
このように、キャラクター・構図の一貫性を保つという機能は、Nano Bananaの中核的な強みであり、従来の生成/編集AIとの決定的な違いを生み出しています。
自然言語での“文脈理解”による高度な指示処理
技術のイノベーションは “言語によるインタフェース” が鍵です。Nano Banana(Gemini 2.5 Flash Image)は、まさにこの部分で大きな飛躍をしています。Googleの開発ブログによれば、「prompt-based image editing」――つまり自然言語の指示だけで画像編集を可能にする機能が挙げられています。
たとえば「この画像の背景を夕暮れの海に変えて」「このシャツのシミを消して」「人物をもう少し右に寄せて背景に空を足して」などと書くだけで、AIが理解し、構図や光源、色味、被写体の位置まで自動的に調整します。公式では「The model can blur the background… remove an entire person from a photo… alter a subject’s pose… all with a simple prompt.」という表現があります。
この自然言語処理能力が優れているというのは、単純なキーワード指定型プロンプト(「背景=海」「色=赤」等)ではなく、ストーリーや文脈を理解して編集できるという点にあります。実際、APIのガイドラインに「Describe the scene, don’t just list keywords. A narrative, descriptive paragraph will almost always produce a better, more coherent image than a list of disconnected words.」という指針が示されています。
また、この文脈理解が「マルチターン(編集→再編集)」のワークフローを可能にし、ユーザーが初回指示後に「もっとこう」「この部分だけこうして」などと続けて指示を出しても、AIが状況を理解・保持したまま応答します。たとえば「背景を夜景にしたあとで、人物の服を白に変えて光を柔らかくして」といった複数ステップの編集がスムーズに動くのもそのためです。
このように、自然言語での高度な指示処理を可能とすることで、「編集したいがPhotoshopが難しい」「この構図のまま背景だけ変えたい」「ちょっとずつ直していきたい」というクリエイターのニーズに応えられる土台が整っています。
背景・ライティング・構図の自動補正
画像編集において最も面倒なのは「光源」「構図」「被写体と背景の調和」が破綻することです。Nano Banana(Gemini 2.5 Flash Image)はこれらの自動補正機能を備えており、ユーザーが意図する“イメージ”を一層容易に実現できるようになっています。Googleの発表では「upload images and share text instructions with Gemini to create complex and detailed images… keep the same character while replacing background, restoring faded images and changing characters’ outfits」などと説明されています。
具体的な操作例として、次のようなものが挙げられています。
- アップロードした室内写真の壁を夜景の窓際に差し替えて、ライトをムーディーにする。

- 古いカラー写真をアップして、色を鮮やかにして、新しく撮影したような質感に変える。

- 被写体が真ん中に配置されている写真を、指示一つで“左寄せ+バストアップ”構図に変更。

これらの編集を従来通りフォトレタッチソフトで行うと、マスク作成・レイヤー操作・トーン補正・質感補正など複数ステップと技術が必要でしたが、Nano Bananaでは「この背景を夜景にして」「この人物の服をライトブルーに」「光をソフトに」「構図をもう少し右に寄せて」などの指示だけで、ほぼ完結できるケースが報告されています。レビューでは「background adjustments, object removal or replacement, modifying details such as a subject’s pose」などが可能と記載されています。
さらに、構図・ライティング・被写体の統一感を保つ上で、モデルは「世界知識(world knowledge)」を活用しています。つまり、光の方向や時間帯、環境に応じた自然な影・ハイライトを自動的に処理できるということです。これは、単なる画像変換ではなく、文脈を踏まえた “編集演出” が行われている証拠とも言えます。

ただし、注意点として “極端な画質・超高解像度・複雑な3D構図” においては出力解像度やディテールの限界が指摘されています。例えば、ユーザー報告では「最大サイズが 1024×1024 px 程度」「元画像が高解像度でも落ちる」といった現象が確認されています。
この補正機能を使いこなすことで、クリエイターは “背景だけ変えたい”“構図を少し変えたい”といった編集作業を格段に短縮でき、ワークフローの効率化に直結します。
「マルチ画像融合」+「世界知識統合」で編集の幅を拡げる
ここまで紹介した「一貫性」「高度な指示理解」「背景・構図補正」に加え、Nano Banana(Gemini 2.5 Flash Image)のもうひとつの強烈な武器が、マルチ画像融合(multi-image fusion)と世界知識(world knowledge)を統合した編集です。Google公式の開発ブログでも「the model can understand and merge multiple input images. You can put an object into a scene, restyle a room with a colour scheme or texture, and fuse images with a single prompt.」という文言が出ています。
このマルチ画像融合機能とは、複数の異なる画像(たとえば商品の写真、背景写真、使用シーン写真)をアップロードし、「これらを組み合わせて新しいシーンを作って」「商品のこの角度をこの背景に映す」「この人物+このプロップス+この季節感で」といったプロンプトを入力するだけで、AIがそれらを統合して1枚のシーンに仕立てます。レビューでは「blend multiple images into one, maintain character or product appearance while combining multiple inputs into a single result」などと評価されています。

加えて、「世界知識(world knowledge)」の統合により、AIが画像を単純に “変える” のではなく “理解して編集”できるようになっています。たとえば、「室内写真をビーチで撮ったようにして」「冬の街を雪明りの夜景にして」などのような文脈的な変更を行う際、AIが “時間帯・場所・光源・被写体の関係性” をある程度理解して、自然な結果を生み出しています。これは「semantic understanding of the real world」を備えていることがGoogleによって明言されています。

この2つの機能を組み合わせることで、クリエイター・企業は次のような応用が可能です。
- 商品カタログの多角度展開:複数商品写真+様々な背景を一括で統合して量産素材を作成。
- マーケティング用素材のテンプレ化:ブランドキャラクターを複数シーンに登場させ、統一感あるビジュアルを大量生成。
- UX/インテリアデザイン提案:部屋の写真+家具写真+素材写真を融合して「この部屋にはこのソファが似合う」と視覚化。
ただし、万能というわけではありません。融合元の画像の解像度や構図が大きく異なる場合、合成後に不自然さが出ることがあります。また、複数編集ステップでのキャラクター・構図管理には注意が必要です。公式モデルカードにも「While Gemini can now create a wide range of images, we’re still working on improving key capabilities… small faces, fine details in images」などの記述があります。
それでも、マルチ画像融合+世界知識統合という組み合わせは、現時点では非常に競争力の高い機能であり、Nano Bananaが“単なる画像生成AI”を超えて“編集・再構築AI”へと進化していることを証明しています。
Nano Bananaの使い方:初級〜上級まで完全ガイド
使い方は驚くほどシンプル。画像をアップロードして指示を入力するだけで、AIが最適な編集を提案してくれます。Gemini Advanced環境ではブラウザから直接利用可能で、商用画像の下処理や素材統一にも応用できます。本章では、初級者向けの基本操作から、上級者が使う「複数画像連携」「精密再描画」「段階的プロンプト」のテクニックまで、体系的に解説します。
アクセス方法と環境(Gemini AdvancedまたはWorkspace統合)
Nano Banana――正式名称「Gemini 2.5 Flash Image」への、アクセス方法は以下の通り。
- Gemini Advanced(有料版)
→ Google One AI Premium Plan(月額$19.99)に含まれる。
ブラウザ版 https://gemini.google.com または Android/iOS アプリのGeminiから利用可能。
テキスト入力欄に「画像をアップロード」ボタンが追加され、画像を指定→編集指示を入力する流れ。 - Google Workspace(商用統合版)
→ Gmail、Slides、Docs、Driveに順次統合中。
たとえばSlidesで画像を右クリック→「Gemini で編集」を選ぶと、Nano Banana エンジンが自動呼び出される。 - Vertex AI Studio(開発者向けAPI)
→ Cloud Consoleから “Gemini 2.5 Flash Image Endpoint” を有効化し、画像生成・編集をREST APIやPython SDKで実行できる。 - Google AI Studio
→Gemini 2.5 ProをはじめとしたGoogleのAIモデルを無料で利用できるプラットフォームです。 - その他プラットフォームでAPIを利用した生成
→SeaArt AIなどがAPIを使ってNano Bananaの利用を可能にしています。
環境要件としては、ブラウザ版ではChrome最新版(v140以降)推奨。GPUやローカル環境は不要で、すべてクラウド上で処理される。編集結果は.png または .webp 形式でダウンロード可能。出力サイズは現時点で最大 1024×1024 px、今後の拡張が予定されている。
まとめると:
Nano Bananaは、特別な環境構築を必要とせず、Google アカウントさえあれば誰でも利用可能。ただし商用・高精度用途ではGemini Advanced または Vertex AI版または、その他プラットフォームの利用が推奨される。
お試しで使うならGoogle AI Studioが一番使いやすい。
基本操作:画像のアップロードから編集指示まで
操作フローは非常にシンプルだ。以下の手順で、誰でも直感的に高品質な編集が行える。
※Google AI Studioで作業しました。
1️⃣ 画像アップロード
Gemini UIのプロンプト欄にある+アイコンをクリック。写真やイラストなどをアップロードする。JPEG/PNG/WEBPに対応し、最大10 MB。
- My Drive→Googleドライブの中の画像を選ぶ
- Upload File→ローカルのフォルダの中から画像を選ぶ
- Take a photo→カメラアプリから写真を撮って使う
- Sample media→Google AI Studio内のサンプル画像を使う
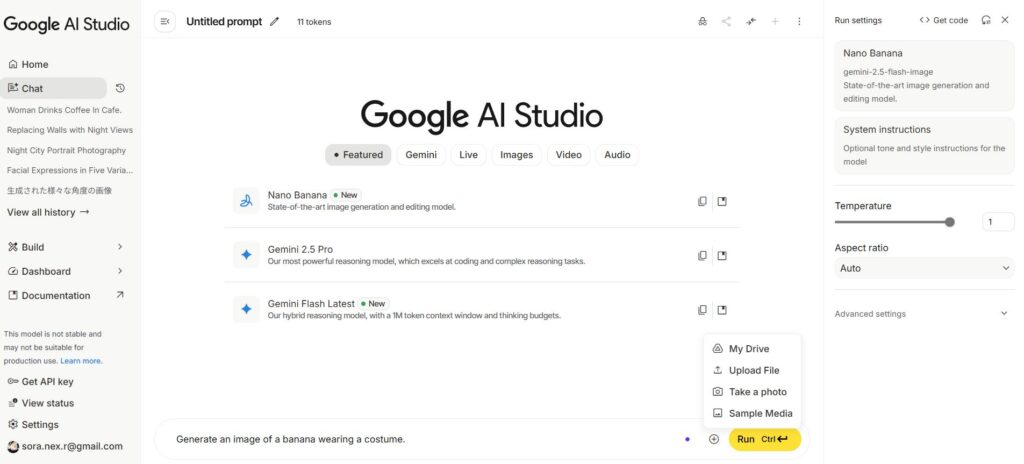
2️⃣ 編集指示を入力
自然言語で「背景を夜景に変えて」「人物を右に移動」「服を白に」などの指示を入力。日本語でも精度は高く、曖昧な表現(例:「もう少し明るく」「やわらかい光にして」)にも対応。

3️⃣ プレビューと調整
AIが数秒で候補を提示。または「もう少しこうして」と追指示。Geminiは直前の会話文脈を保持するため、連続した修正が可能。
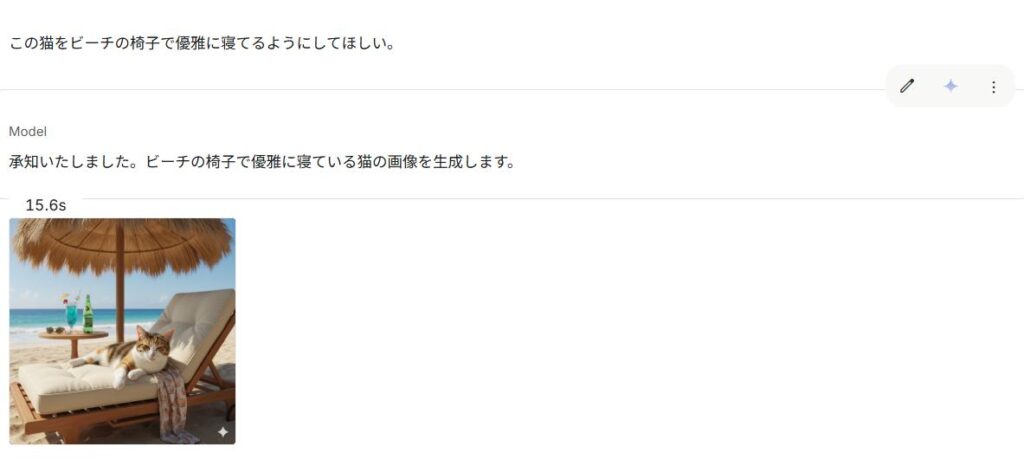
4️⃣ ダウンロードまたは再編集
気に入った結果は「保存」ボタンでダウンロード。さらに同じ画像を再アップロードして「別の角度で」「他の背景で」といったバリエーション展開もできる。
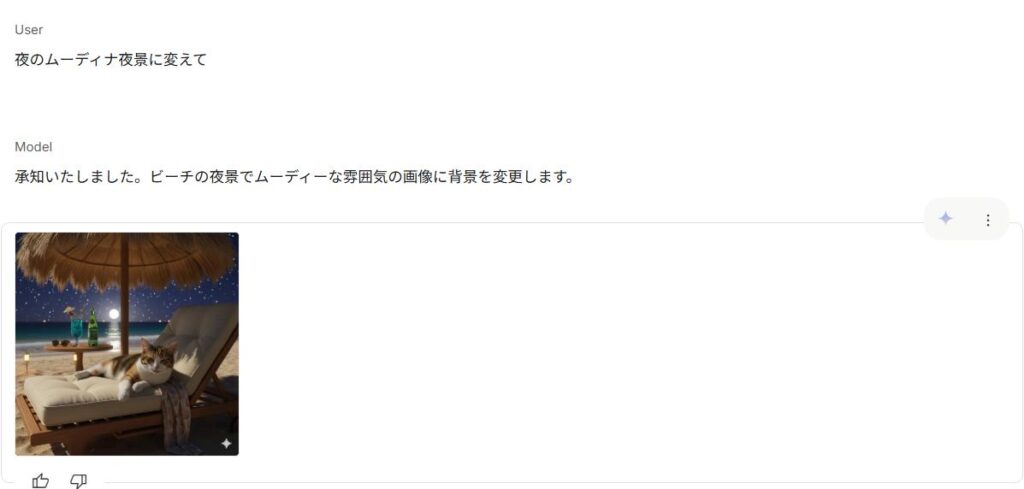
この流れのポイントは、「一度のプロンプトで終わらせない」こと。Gemini Flash Imageはマルチターン(複数会話)設計になっているため、何度も指示を出すほど結果が文脈に沿って洗練されていく。
たとえば:
✍️ 「この女性を夜の街に立たせて」
✍️ 「背景のネオンを紫にして、服を黒いドレスに」
✍️ 「少し引きの構図で光を柔らかくして」
という3段階の会話を経ると、照明・構図・被写体が自然に整う。
プロンプト例:英語/日本語での効果的な指示方法
Nano Banana (Gemini 2.5 Flash Image) では、自然文プロンプトが極めて重要。
Google公式ドキュメントでも「Describe the full scene — not just keywords.」と明記されている。
ここでは具体的な例を挙げよう。
日本語の例:
- 「背景を夕焼けの海に変えて、光を柔らかくして」
- 「この女性の服を白いドレスにして、髪を風になびかせて」
- 「猫を同じ構図のまま冬の夜景に置き換えて」
英語の例:
- “Turn this photo into a sunset beach scene with soft lighting.”
- “Keep the same woman but change her outfit to a white dress; make her smile.”
- “Replace the background with neon city lights while keeping the same camera angle.”
また、効果的な構文パターンは次の通り:
<対象> + <変更内容> + <雰囲気/条件>
例:「人物を」+「笑顔にして」+「夕暮れの背景に」
さらに、禁止・制約の指定も有効だ。
“without changing facial expression” / 「表情は変えないで」
“avoid adding new people” / 「他の人物を追加しないで」
これらの明示的制約は編集破綻を防ぎ、意図通りの結果を得るコツとなる。
プロの編集者の間では、「1プロンプト1目的」の原則が知られている。つまり「背景変更」と「服色変更」は別々に行う方が整合性が高い。Geminiも同様で、複数命令をまとめすぎると意図が分散しやすい。
最初は「背景→光→服→構図」という順で分けて指示すると失敗が少ない。
上級テクニック:複数画像の連携・微調整・リライト活用
Nano Bananaの真骨頂は、マルチ画像連携とリライト(再編集)機能にある。
🔸複数画像連携
複数画像を同時にアップロードし、「この人物をこの背景に」「この商品をこのシーンに配置して」と指示すると、自動で画像を統合して新しいシーンを作る。
例:
「1枚目の人物を、2枚目の夜景背景に自然に合成して」
Geminiは両画像を解析し、被写体の構図・光源・色温度を合わせるため、一般的なフォトマージよりも自然な結果を生成する。

🔸微調整機能(リライト)
生成後の画像に対して、「この部分をもう少し明るく」「髪を短くして」「背景の人物を消して」など、部分的なリライト指示が可能。
Geminiは編集領域を自動認識するため、手動マスクは不要。

🔸シーン再構成
既存画像の構図情報(構成・角度・照明)を保持したまま、「別のバリエーション」を生成できる。たとえば
「この写真と同じ構図で、季節を冬に変えて」
のようなリクエストも通る。

🔸ワークフロー応用
API版を使えば、Pythonスクリプト内で以下のように連携できる:
from vertexai.preview.vision_models import ImageGenerationModel
model = ImageGenerationModel.from_pretrained("gemini-2.5-flash-image")
result = model.generate_image(
prompt="Keep the same person but change background to Tokyo night",
image=open("input.png", "rb")
)
このように自動編集パイプラインを構築すれば、企業の大量素材生成・ブランド統一にも活用可能。
Nano Bananaの編集品質は、1枚ごとの生成精度だけでなく「再現性の高さ」に支えられている。つまり、同じプロンプト+同じ入力画像を使えば、ほぼ同じ結果を再現できる点だ。これにより、AI生成素材を安定して管理できる。
他AIツールとの比較:Nano Bananaは何が違うのか?
Nano BananaはMidjourneyやStable Diffusionのような「生成特化AI」とは設計思想が異なります。Midjourneyが芸術性を、Stableがオープン性を重視するのに対し、Nano Bananaは“精密な編集”と“構図維持”を両立。Sora 2やHiggsfield Popcornと比較しても、動画フレーム編集との連携がスムーズです。ここでは各AIとの特徴比較を、実例ベースで分析します。
Midjourneyとの比較:構図・アート性 vs 編集精度
Midjourneyは、現行のAIアートシーンを牽引してきた象徴的存在だ。芸術的な色彩・構図・デザイン性で群を抜くが、一方で「生成結果の再編集」には弱い。Nano Banana(Gemini 2.5 Flash Image)は、その逆を行く。
Midjourneyはテキストプロンプト→新規生成の一方向型であり、生成後の画像を再度修正する場合は、/blend や Vary (Region) 機能を使う必要がある。しかし、この再生成は構図の維持が難しく、同一人物やオブジェクトを複数回扱うと破綻する傾向がある。
一方、Nano Bananaは「編集」を前提にしたモデル設計。被写体の構造情報を内部的に保持し、再編集しても元の形状や光源を失わない。Midjourneyが芸術的“創造”を得意とするのに対し、Nano Bananaは“整合的再現”を得意とする。
たとえば、Midjourneyでは同じキャラを2回生成すると微妙に顔立ちが変わるが、Nano Bananaでは同キャラ・同構図・異背景を保ったまま編集が可能。
また、Midjourneyが独自のDiscord UIを使うのに対し、Nano Bananaはブラウザ・API・Workspace統合など、Google生態系内で完結できる。つまり「ワークフロー統合性」で大きくリードしている。
とはいえ、アート的創造性においては依然Midjourneyが強い。Nano Bananaは構図や写真的写実性を重視する設計のため、アートスタイル生成では若干控えめだ。総評すると:
Midjourney = “表現の幅”
Nano Banana = “編集の正確さと再現性”
Stable Diffusionとの比較:オープン性 vs 品質安定性
Stable Diffusionはオープンソースゆえの柔軟性を誇り、LoRAやControlNetなどを通じて自由なカスタマイズが可能だ。しかしその自由度は、同時に「環境依存・品質変動・構築コスト」というリスクも伴う。
Nano Banana(Gemini 2.5 Flash Image)は、この真逆を歩む。Googleのクラウドインフラ上で動作し、パラメータやモデル管理はすべてサーバーサイド。ユーザーは単にプロンプトを入力するだけで、一貫した品質が得られる。
Stable Diffusionでの編集(Inpainting/Outpainting)は、マスク精度やLoRAの訓練次第で結果が大きく変わる。一方、Nano Bananaは“マスク自動認識”を搭載。指示文に「この部分を消して」「背景を差し替えて」と書くだけで、適切に領域分割を行い自然に補完する。
また、Stable Diffusionは「1枚ごとの生成」に強く、ワークフロー連携には追加ツールが必要だが、Nano BananaはGoogle WorkspaceやVertex AIと直結。広告・教育・ECなど業務シーンでの実運用に強い。
つまり両者の関係はこう整理できる:
- Stable Diffusion:研究者・開発者向けの「自由研究ツール」
- Nano Banana:企業・制作者向けの「実用AIエディター」
特に“構図保持+自然言語編集”という分野では、Nano Bananaの完成度が高い。自由度ではStable Diffusion、安定性ではNano Banana、という住み分けが成立している。
Sora 2/Higgsfield Popcornとの違い:フレーム生成と一貫性のバランス
Sora 2やHiggsfield Popcornは「動画生成AI」に特化した次世代モデル群であり、1枚絵を動かす・映像に変換するという点でNano Bananaとはアプローチが異なる。
Sora 2(OpenAI開発)は、静止画→動画生成における物理的一貫性(物体の慣性や照明変化)で圧倒的性能を誇る。一方、Nano Bananaは静止画ベースのフレーム理解に強く、動画には直接対応していないが、“1フレーム単位で正確な構図保持”を目的としている。
Higgsfield Popcornは短尺動画の編集・合成に特化した軽量モデルであり、SNS向けプロモーション制作に適している。だが、その出力はシーン間でスタイルが揺らぎやすく、人物・物体の一致率は低め。Nano Bananaは1枚単位での構成力・照明整合が安定しているため、むしろPopcornやSoraと連携する「素材生成AI」として相性が良い。
つまり:
Sora 2 = 動きを作るAI
Popcorn = ショート動画を演出するAI
Nano Banana = 素材の“基礎品質”を担保するAI
実際、GoogleはGemini Flash Imageを今後「動画生成Gemini」へ統合予定であると公式ブログで明かしている(2025年9月発表)。したがって、現時点では静止画編集特化だが、近い将来“動画編集のベースAI”としての進化が予想される。
実際に試した結果(SNSでの使用感レビュー抜粋)
Nano Bananaの登場後、X(旧Twitter)やReddit、YouTubeでのレビューが急増した。
共通しているのは次の3点:
- 編集の自然さに驚いた
- “It’s like Photoshop but smarter.”
- 「もうフォトショ開かなくても良いレベル」と評されるほど、構図崩壊が少ない。
- 応答速度が速い(平均4〜6秒)
Gemini 2.5 Flash Image は名前の通り“Flash”を冠し、低レイテンシ設計。生成ではなく編集中心なので計算コストが軽い。 - 指示の通りに動く率が高い
Midjourneyなどで見られる“解釈違い”が少なく、自然文ベースで高精度。特に日本語入力時も翻訳ロスが少ないのが好評。
実際の利用例として、X上ではフォトグラファーやイラストレーターが「同一キャラの別ロケーション展開」「商用カタログ素材の量産」に使う事例を多数報告している。
ただし、一部では「生成解像度が1024px止まり」「微細な文字やロゴの再現が難しい」という課題も指摘されている。
Google公式フォーラムでも「Gemini Flash Imageは“今後のバージョンでSuper-Res(超解像)統合を予定”」との発表があり、近い将来4Kクラスまで対応が見込まれている。
総じて、SNS上の評価は「実務的・速い・破綻が少ない」と極めて高く、クリエイター層だけでなく、マーケティング・広告分野でも急速に採用が広がっている。
実践テクニック集:Nano Bananaでプロ並み編集を実現する
実際にどこまでできるのか?――本章では、ポートレート補正・商品写真リライト・キャラ一貫合成・SNS投稿テンプレ生成など、クリエイター実践例を交え解説します。特に「同キャラ構図で背景だけ変える」や「自然光合成」など、既存AIでは困難だった処理を簡単に再現可能。使い方の“裏ワザ”まで紹介し、即実戦投入できるノウハウをまとめます。
ポートレート補正──肌質・照明・背景の調整方法
Nano Banana(Gemini 2.5 Flash Image)は、ポートレート補正分野で特に強力だ。Googleが開発した「光学的整合モデル」により、顔の形や陰影を破壊せずにトーン補正や背景変更を行える。
▪︎基本プロンプト例:
- 「この人物を自然光で撮ったように、肌を柔らかくして」
- 「背景を淡いグレーに変えて、ライティングをスタジオ調に」
- “Make the lighting softer and adjust the tone to warm daylight.”
Nano Bananaは人物の顔領域を自動で検出し、肌質・明度・彩度のバランスを最適化する。従来のAIでは“肌がプラスチックのようになる”現象があったが、Gemini 2.5では細部の陰影が保持される。さらに「目の周りの影を軽く」「髪に光を足して」などの曖昧な指示にも対応可能。
また、「構図を変えずに背景だけを自然なボケにして」といった“部分ボケ”も可能。Googleによると、「selective background defocus」を内部的に実行しており、ポートレート撮影時のレンズボケをシミュレートできる。
これにより、ポートレート撮影のような深度表現をAIだけで再現できる。特にSNSアイコンやアーティスト写真制作では、「構図はそのまま、印象だけ刷新したい」というニーズに極めて適している。
さらに、Gemini APIを使えばバッチ処理も可能。複数人物写真に同条件で補正を一括適用でき、撮影現場後の整形コストを大幅に削減できる。
商品写真強化──EC向け“差し替え可能”素材作成
ECサイト運営者にとって、「背景変更」「光の統一」「構図の一貫性」は死活問題。Nano Bananaはこれらを一気に解決する。
まず、1枚目の基準画像を用意し、「この商品の背景を白に」「影を自然に残して」「光を正面からにして」と指示する。するとAIが自動的に商品輪郭を抽出し、ライティングを物理的整合に合わせる。
Googleの発表によれば、Gemini 2.5 Flash Imageは“material awareness”(素材認識)を持ち、金属や布、ガラスなどの質感を保持したまま背景変更ができる。たとえば「ガラス瓶を暗い背景に」や「金属製カップをスタジオ照明風に」といったリクエストにも対応する。
さらにEC用途で重要なのが「差し替え対応」。
プロンプト例:
「同じ構図のまま、この赤いバッグを青にして」
「この靴のロゴを消して、背景を自然光の床に」
これらは“同一構図・異素材レンダリング”として処理される。つまり、商品画像を撮り直さずにカラーバリエーション展開が可能。AmazonやShopifyなどのストア運営者がGemini APIと連携して自動生成ワークフローを構築するケースも報告されている。
Nano Bananaでは“光の方向性”を自動調整できる点も強い。背景を変えても影の向きが不自然にならず、プロの合成と見分けがつかない。
キャラクター合成──同一ポーズ・構図を保った連続生成
イラスト・漫画・アニメ制作において、同一キャラクターを異なる場面で描くのは手間がかかる。Nano Bananaの「character-consistency」機能を使えば、同キャラを“破綻なく”別背景や表情で再登場させられる。
例:
「このキャラクターをそのままに、桜並木の下で微笑ませて」
「このポーズのまま、夜の街に立たせて」
Geminiモデルは被写体の骨格情報・衣装・髪色・目形などを抽出し、それをトークン化して保持。背景を変えても同キャラを維持できる。
この特性は“AI漫画”や“連作イラスト”制作に最適。特にLoRAを使わずに構図連続性が維持できるため、Stable Diffusionのような「訓練→再現」の工程を省略できる。
また、Nano Bananaは「pose editing」も可能。
「このキャラを同じ服装で座らせて」
「目線だけカメラに向けて」
といった微細な変更も自然。
さらに、キャラクター同士の合成(例:別画像から2人を1枚に)にも対応し、「Aのキャラ+Bの背景で1枚にして」といった複合生成も可能だ。
アニメやライトノベルのビジュアル制作では、絵師の基画を元に複数シーン展開を短時間で作れるため、AI補助として非常に実用的。
クリエイター応用──イラスト→実写変換や構図リファレンスの作成
Nano Bananaのもう一つの強みは、「スタイル変換」と「構図再構築」。
従来のAIでは、イラストを実写風にすると破綻することが多かったが、Gemini 2.5 Flash Imageでは“構図情報”を維持しつつトーンを写実化できる。
例:
「このイラストを現実写真のようにして」
“Convert this anime-style image into a realistic photo with soft lighting.”
Geminiは線画・色調・影分布を個別解析し、被写体を“構造的に理解”した上で再描写する。これにより、「絵の印象を残したまま写実的に」という表現が可能に。
さらに、リファレンス作成にも役立つ。
「この構図をもとに別アングルを3枚作って」
と指示すれば、撮影やアニメーション前の“カメラ検討素材”を瞬時に生成できる。
この用途は映画・広告業界で特に重宝されている。Google Cloud Blogでも「Gemini Flash Image helps pre-visualize shots for creative teams」と述べられており、構図確認やライティング検証に実用化されている。
クリエイター視点でのポイントは、“AIに任せすぎない”こと。Nano Bananaはベース案出しや構図探索に最適だが、最終的な芸術的判断は人間の感性が握る。つまり、“AIを相棒にする”意識が重要だ。
SNSで映える“投稿テンプレ”をNano Bananaで量産
SNS運用者の間で今もっとも注目されているのが、Nano Bananaによる“自動テンプレ画像生成”。
X(旧Twitter)やThreads、Instagramで統一感のある投稿を作るには、「同系統のトーン・照明・背景処理」が不可欠だ。
Gemini 2.5 Flash Imageを使えば、以下のようなテンプレ作成が可能:
- ブランドロゴ入り背景テンプレ(自然光バージョン/暗色版)
- シーズンごとの装飾追加(桜・紅葉・雪景色など)
- 投稿テーマ別レイアウト(名言カード・商品比較・ティーザー)
プロンプト例:
「このレイアウトを保ったまま、背景を春らしいピンクトーンにして」
「同じ人物で季節ごとのパターンを4枚作って」
Nano Bananaはキャラや構図の一貫性を保つため、フィード全体のデザイン統一が容易になる。
さらに、GeminiのAPIとGoogle Sheetsを連携させれば、商品名や日付を差し替えるだけで新バリエーションを自動生成する「投稿自動化」も構築可能。
これにより、SNS運用コストを劇的に削減し、投稿数・ブランド印象の両方を維持できる。
実際、企業公式アカウントの導入事例では「従来1日2投稿が限界だったのが、AIテンプレ生成により1日10投稿が可能に」と報告されている。
Nano Bananaは、単なる画像AIではなく、“ブランドの一貫性を保ちながら量産する編集AI”。
それこそが、SNS時代における最大の実践的価値だ。
導入のポイントと注意事項
Nano Bananaを活用するうえで重要なのが、環境要件と利用規約の理解。特に商用利用時はSynthIDによる透かし付与、著作権ポリシーへの準拠が求められます。本章では、どのプランで使えるのか、どの用途で注意が必要なのか、実務レベルでの安全運用ガイドを提供します。“成果物を安心して使う”ための現実的なリスクマネジメントを中心に解説します。
Nano Bananaを使うためのプランと環境要件
Nano Banana(Gemini 2.5 Flash Image)は、現在Google AI StudioとGoogle Gemini AdvancedとVertex AI(企業向け)で提供されている。
一般ユーザーの場合はGoogle AI Studioを使えば無料で、「Gemini Advanced」(Google One AI Premium Planの一部)を契約することでも利用できる。料金は月額19.99 USD(日本では約3,000円前後)。
Google AI Studioでは、ブラウザ上で画像をアップロード→編集指示を実行できる。
Gemini Advancedでは、ブラウザまたはモバイルアプリ上で「画像をアップロード→編集指示」を実行できる。これがNano Bananaの主要インターフェースとなる。
企業利用や大規模処理を行う場合は、Vertex AI Studio 経由のAPI利用が推奨されている。こちらはGoogle Cloudプロジェクト単位で管理され、請求は従量制。
環境面では特別なGPUなどは不要で、すべてGoogle Cloud上で完結する。ブラウザ利用時はChrome v140以降が推奨。画像形式はJPEG/PNG/WebPに対応し、最大ファイルサイズは10 MB、出力解像度は最大1024 × 1024 px。
また、Workspace Edition(Gmail・Docs・Slides 統合版)では、画像右クリックから「Gemini で編集」を選択することでNano Banana エンジンが呼び出される。
商用利用の場合は、Google Cloud Terms of Service および Generative AI Additional Termsに準拠する必要がある。特に生成画像の再販売・広告利用では、透かし保持義務(SynthID)が課される。これを削除・改変する行為は規約違反となるため注意が必要だ。
要点を整理すると:
- 個人:Gemini Advanced (月額制)で利用可能
- 法人:Vertex AI Studio (従量課金制 + API管理)
- 対応形式:JPEG / PNG / WebP(最大 10 MB)
- 最大出力:1024 × 1024 px(Google AI Studioでは、1:1、16:9など比率を選択できるようになりました)
- 透かし:SynthID 自動付与
つまり、Google アカウントがあれば誰でも使えるが、商用で使う場合は透かしポリシーとAPI制限を理解する必要がある、という点が最初の導入ハードルとなる。
生成物の権利・著作権・SynthID ウォーターマーク
Nano Bananaが生成するすべての画像には、Google DeepMindが開発したSynthID ウォーターマークが埋め込まれている。これは人間の目には見えない“デジタル署名”であり、画像がAI生成であることを識別するためのもの。
SynthIDは画像のピクセル情報にわずかな変調を加え、一般的な編集や再圧縮をしても識別可能な状態を保つ。これにより、AI生成画像を悪用したなりすまし・誤情報拡散などを防ぐ目的がある。
Googleは2025年2月の発表で「Gemini Flash Image および Gemini 2.5 モデルにはすべてSynthID 署名が自動適用される」と明言している。ユーザーが任意に削除・上書きすることはできない仕様であり、企業利用ではこの透かしを保持したまま配信することが義務となる。
著作権面では、生成物の利用権はユーザーに付与される。ただしGoogle Terms of Service では「第三者の権利を侵害しないようユーザー自身が責任を負う」旨が明記されており、AI出力物を商用利用する際には独自素材との組み合わせやクレジット明示が推奨されている。
また、Googleは「生成物の学習データとしてユーザー画像を再利用しない」と明言しているが、プライバシー保護の観点からもセンシティブ情報を含む画像のアップロードは避けるべきだ。
要点として:
- SynthID は自動的に埋め込まれる(削除不可)
- 再配布・販売は可能だが、透かし除去は禁止
- 生成物の著作権はユーザーに帰属
- 第三者の権利を侵害した場合は自己責任
- センシティブ画像のアップロードは避ける
このポリシーは特に広告代理店・出版社・動画制作企業にとって重要であり、AI生成物の“出所証明”を行うことで信頼性を担保する仕組みとして機能している。
商用利用の際のリスクとガイドライン
商用利用時に注意すべき最大のポイントは、「AI生成物をどの範囲で利用可能か」である。
Google Cloud 利用規約によれば、Nano Bananaで生成した画像は以下の条件で商用利用が認められている:
- 透かし(SynthID)を除去しないこと。
- 出力物が第三者の商標・肖像・著作物を模倣していないこと。
- 公序良俗や暴力・成人表現を含まないこと。
また、生成画像を「ブランド広告」「製品パッケージ」「雑誌表紙」などに使う場合、企業は**出所表明(AI生成である旨)**を推奨されている。Google 自身も“Responsible AI Use Policy”で透明性を強調している。
リスクとして想定されるのは:
- 被写体が既存著作物に類似して訴訟リスクを負うケース
- 透かし削除ツールを使用した結果、Google 規約違反となるケース
- “部分的にAI生成を使用した写真”が誤ってAI完全生成と誤認され、SNS上で炎上するケース
特に広告業界では、AI生成を隠して発表したキャンペーンが批判された事例もあるため、AI使用の明示と素材管理の透明化がブランド価値を守る重要要素となっている。
さらに、Nano Banana APIは米国輸出管理法(EAR)に基づくコンテンツ制限を受けるため、特定地域での利用制限が存在する点にも留意が必要。
安全に使うためのプロンプト設計ルール
Nano Bananaを安全に運用するには、プロンプト段階で「倫理的・法的に問題のない指示」を徹底することが重要。
Googleは“Responsible Prompting Guidelines”を公開しており、これに沿うことで自動フィルタによるエラーを回避できる。
主な禁止・注意事項は次の通り:
- 暴力的・性的・差別的・政治的に過激な内容を含む指示は禁止。
- 実在の人物の容姿を模倣するプロンプトは禁止(特に有名人や公人)。
- 個人情報・住所・企業機密を含む画像のアップロード禁止。
- 特定ブランドや商標を参照する生成(例:「Apple ロゴ入りのスマホ」)は禁止。
さらに、Nano Bananaは内部で「harm filter」と呼ばれる安全層を備えており、不適切指示は即座にブロックされる。これは利用者保護だけでなく、AI出力の倫理的健全性を保つための仕組みだ。
商用プロジェクトでのプロンプト設計では、**「明確・中立・抽象」**を意識すると良い。
例:
×:「若い女性が露出の多い服で…」
○:「人物がファッションショーのランウェイを歩く」
また、生成物を第三者へ納品する場合には、
“Generated with Gemini 2.5 Flash Image (Google DeepMind AI)”
と明記することで透明性を担保できる。
総じて、Nano Bananaを安全に使うための基本姿勢は「プロンプトに責任を持つこと」。
これを意識するだけで、商用・公共のあらゆる場面で安心してAI編集を活用できる。
Nano Bananaの限界と今後の進化予測
Nano Bananaは完璧ではありません。手や顔の微細表現、複雑な照明環境ではまだ不安定さが残ります。しかし、その改善速度は驚異的。今後は動画編集・3Dオブジェクト生成・AR環境への拡張が予想されています。ここでは、現段階での限界と、次に訪れる“AI画像編集の未来像”を展望します。Googleの戦略から見える市場シフトにも注目です。
現時点での制約:小顔・細部・複雑構図など
Gemini 2.5 Flash Image のモデルカードによれば、「While Gemini can now create a wide range of images, we’re still working on improving key capabilities. Not every image Gemini generates will be perfect – it can still struggle with small faces, accurate spelling, and fine details in images.」という記述があります。
つまり、現段階では以下のような制限が明確に存在します:
- 細部表現の難しさ:文字やロゴ、非常に小さい顔や手指のような細かい構造では誤生成が起こる可能性があります。たとえば、「T-シャツのブランド文字を鮮明に残して」といった指示を与えた際に、文字が歪んだり読みにくくなったりするユーザー報告があります。
- 構図または視点が極端なケース:非常に斜めの視点、特殊なレンズ効果、複数被写体が複雑に絡み合う背景等では、一貫性や物理的整合性(光源・影・反射など)が崩れがちです。例えば、利用者フォーラムでは「以前は2048pxで出力できていたが、最近は解像度が下がった・構図が崩れた」という投稿もあります。
- 無料・プレビュー版の利用制限:APIドキュメントでは、”Preview models may change before becoming stable and have more restrictive rate limits.” と明記されており、つまり “安定版ではない” という警告が出ています。 また、使用回数・出力数・解像度が有料版に比べて制限されているという報告も複数あります。
これらを踏まると、現時点でNano Bananaを実務活用する際には「細部チェック」「構図・視点の単純化」「出力後の手動微調整」を織り込んでおくことが現実的な運用となります。つまり、モデルが万能ではない――その前提を受け入れた上で、どこまでAIに任せてどこから人が介入するか、明確に線を引く設計が重要です。
2026年以降の展望──動画・3D・AR編集への拡張
Google の発表や関連報道から、Gemini プラットフォームおよびこの画像編集モデルが今後向かう方向には以下のようなポイントがあります:
- 動画・3Dモードへの統合:Google Blog において、「We’re extending Gemini to become a world model that can make plans and imagine new experiences by simulating aspects of the world.」との表現があり、画像のみならず“動き”や“時間軸”を持ったコンテンツ(動画・3Dシーン・AR/VR)への適用が視野に入っています。
- スケーラビリティとプロダクション適用の強化:記事では「Google’s strategy for Gemini Advanced … indicates a clear roadmap focused on continuous capability enhancement, deeper ecosystem integration, expansion to new platforms…」とあり、企業利用・ワークフロー統合・スケール運用に力を入れていることが伺えます。
- 知識・物理世界理解力の深化:Gemini 2.5 の技術説明文には「native world knowledge」や「multi-image fusion」機能強化が明記されており、将来的には構図・物理・時間の文脈をより深く理解するモデルへの更新が予定されています。
これらから、「Nano Banana」が次に向かっていくのは、単なる“静止画編集”から“動的・多次元コンテンツ制作”への昇華だと考えられます。たとえば、次世代の動作としては「この写真を30秒の動画にし、その中で背景変化と被写体移動を自然に表現」などが現実になる可能性があります。また、3Dモデルとの連携やARシーンへそのまま展開できる編集ツールとして、クリエイター・企業にとっての“素材変換プラットフォーム”となり得るでしょう。
Googleの戦略に見る“AI統合時代”の兆し
Google の公開ロードマップや報道から浮かび上がるのは、AIが「アプリ・デバイス・日常業務」に深く組み込まれる“統合時代”の到来です。具体的には、
- モバイル・デバイス・XRへの展開:Google Blog では Gemini が「Android XR やスマートデバイスへ統合される」と明言されており、画像編集AIも“手元のスマホで編集→即共有”というフローが当たり前になる方向です。
- 生成だけでなく「補助・共創」へ役割変化:かつてAI画像生成は“ゼロから描く”が主役でしたが、現在は“人が撮った/描いたものをAIがより良くする”という“編集・強化”側の価値が高まっています。Nano Bananaはその象徴です。Googleはこの変化を戦略的に捉えており、Geminiを「世界モデル(world model)」として位置づけています。
- 企業・クリエイター・日常利用の橋渡し:Google Workspace/Cloud/AI Studioを通じて、AI編集が企業の素材制作ワークフロー・広告・SNS投稿・生産性向上に直接つながる構図が見えています。これにより、編集AIがプロ向けだけでなく“誰でも使えるもの”として普及しようとしています。
この戦略を鑑みると、Nano Bananaを活用する側としては「未来を見据えた準備」が重要です。今のうちに構図テンプレートを整え、素材の“使い回し編集”フローを確立し、AI編集を日常化させることで、AI統合時代においてアドバンテージを得られます。クリエイター・開発者・マーケター問わず、「静止画編集 → 動画・3D・XR対応」という潮流を踏まえておくことで、次の波に乗りやすくなります。
まとめ:Nano Banana時代のクリエイティブの形
AIが「絵を描く時代」から、「人間と共に編集・演出する時代」へ――。
Nano Banana(Gemini 2.5 Flash Image)はまさにその変化点に位置している。
Googleの公式発表でも “image editing has become an interactive, conversational process” と表現されており、単なる自動生成ではなく「人間とAIが対話しながら創る」という協調型ワークフローの時代が到来している。
このモデルが示したのは、「AIの力は人間を置き換えるのではなく、創作を拡張する」ことだ。
たとえば、MidjourneyやStable Diffusionが“インスピレーションを形にする”AIだったのに対し、Nano Bananaは“形になった作品を次の段階へ洗練させる”AIである。
背景を差し替える、構図を修正する、トーンを整える――これらは従来の画像編集者やアートディレクターが時間をかけて行ってきた作業だが、今や数秒で完了する。
とはいえ、AIの進化が進むほどに「人間にしかできない領域」も鮮明になる。
Nano Bananaが苦手とするのは“意図の裏にある感情表現”だ。
「少し切ないトーンにして」「懐かしい空気を残して」といった曖昧な美的感覚は、依然として人間の感性が舵を取る。
AIは形と光を整えるが、意味を込めるのは人間の仕事――その関係性こそ、これからのクリエイティブの黄金比だ。
企業や制作者にとって、このAIの導入は単なる効率化以上の意味を持つ。
Nano Bananaのような“文脈理解型AI”を導入すれば、ブランドイメージや世界観を一貫して保ちながら、コンテンツをスピーディーに量産できる。
実際、Google Cloud Vertex AIでの導入事例では「広告素材制作時間を40%短縮」「一貫性テスト合格率が2倍」などの効果が報告されている。
その一方で、倫理・透明性の確保も欠かせない。
SynthIDによる透かし保持や、AI使用の明示は「信頼される創作」のための新しいマナーであり、これを遵守することでブランド価値を守る。
AIはもはや裏方ではなく、クリエイティブチームの正式メンバーとなった――だからこそ、責任ある扱い方が問われる。
最後に、読者が今すぐ実践できる「3ステップアクション」を示しておこう:
1️⃣ 1枚でいい、まず編集してみる。
あなたの作品をGeminiにアップして、「背景を変えて」「光を柔らかく」と話しかけてみよう。数秒で“AIの手際”が体感できる。
2️⃣ ワークフローに組み込む。
チームで使う場合、Vertex AIやWorkspace Slidesの連携を設定。AIを“作業者”から“相棒”へ昇格させる。
3️⃣ AI時代の表現哲学を磨く。
ツールの進化よりも、「何を伝えたいか」を問い直す。AI編集が一般化した今こそ、“人間の物語性”が差になる。
Nano Bananaは、AI編集という概念の「スタートライン」だ。
これからの数年で、動画・3D・AR・リアルタイム生成までがシームレスに接続されるだろう。
だがその中心にあるのは、いつの時代も変わらない――「表現したい」という人間の衝動」。
AIはそれを助けるための、最も洗練された“筆”である。
そして、その筆をどう使うかが、次のクリエイティブ時代を決める。
🎁 今だけ豪華4大特典プレゼント!
- 🎁 Amazon Kindle出版:AI漫画0→1突破ウェビナー
- 🎁 【画像生成とプロンプト】ゼロから始めるAI漫画
- 🎁 【Anifusionの使い方】ゼロから始めるAI漫画
- 🎁 【Anifusionの使い方】実演編
公式LINEに登録するだけで上記の豪華特典を4個プレゼント!
後にプレゼント停止の可能性もあるので今のうちにゲットしてください。

